ON THIS PAGE:
IFS OI Server's key reason for existing is to get your data from any source and show its relationships, all with impressive speed, in a way that applications can easily consume it.
IFS OI Server provides 4 main ways of working with data:
- Aggregation: Aggregate data from multiple systems and allow access through a common interface
- Modelling: Time-aware models of real world assets and their relationships
- Model real world assets and how they change over time
- Model the relationships between these real world assets and how they change over time
- Transformation: Configure free-form calculations over the aggregated data in order to transform it as needed
- Data Mapping: Map data from multiple systems onto the time-aware models to present a complete representation of an asset
Getting Data
A configured connection to an external system via an adaptor is called a datasource. The configuration of the datasource (i.e. the parameters required to connect to the external system) is done in IFS OI Server Management.
There are two types of data that are being currently supported, time series data and tabular data.
Time Series Data
Time series data is data that is in the form of tag name, timestamp, and value. This type of data is most commonly used for storing data about continuously changing information, at a particular point, at a particular time. Temperatures, pressures, and production flow rates are all common examples of this type of data.
A time series adaptor is the mechanism by which IFS OI Server connects to an external system and retrieves time series data. Time series adaptors are used to retrieve data from real-time and historical data sources from a plant historian, such as PHD, PI, etc.
Tabular Data
Tabular data refers to data that is not specifically assigned a tag name and timestamp, as is time series data. This type of data is commonly used for Business Intelligence (BI) reporting, where data has been aggregated, summed, approved etc, and it now exists in a common database (rather than a time series historian).
There are also a lot of other cases where the data is not suited to the time series format, such as lists of items, items that have no distinct time such as monthly accounting data, or data that has relationships other than time (such as downtime causes and reasons).
IFS OI Server natively supports the collection of this type of data from Oracle or SQL Server databases.
So, like time series data, each different database that needs to be connected to is set up as a datasource. The datasource contains information such as the connection username, password, server name etc. Tabular data then differs from time series data in that under each datasource we can then define multiple “datasets”. Each of these datasets is a single SQL statement that returns one table of data. Many of these can be created in each datasource.
Key Components
This diagram shows an overview of the key components of IFS OI Server and how other systems interact with it.
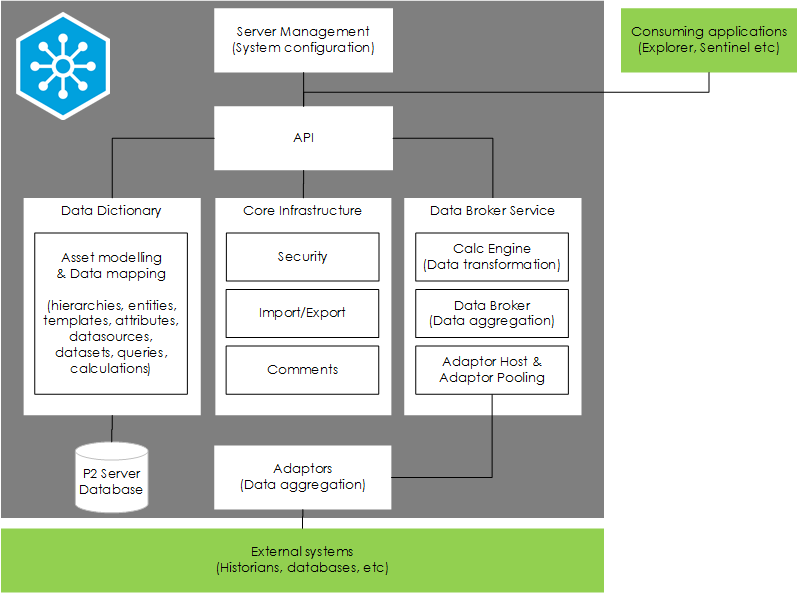
IFS OI Server Architectural Overview
Adaptors
An Adaptor is the mechanism by which IFS OI Server connects to an external system and retrieves data. Adaptors are used to retrieve data from sources such as:
- Real-Time and historical data from a plant historian, such as PHD, PI, etc
- Relational databases such as Oracle and SQL Server
- ERP and maintenance systems
- Laboratory data
- Manually-entered production and operational figures
- Production Allocation and Reporting data
- Results of calculations
The type of source system determines which adaptor is used. For example, to connect to an OSI PI Historian, the PI Adaptor is needed.
Data Broker
The Data Broker is the real brains of IFS OI Server. It aggregates data from multiple systems through a common interface. Depending on the external system, the data can be fetched either in two formats:
- Time series: One data item, over time
- Tabular: Rows & columns, like the result of an SQL query
 The Data Broker works with the adaptor services to collect and interpret requests to the adaptors and pass the returned data to the consuming application, applying any applicable calculations, modelling and transformations before it does so.
The Data Broker works with the adaptor services to collect and interpret requests to the adaptors and pass the returned data to the consuming application, applying any applicable calculations, modelling and transformations before it does so.
The consuming application is completely abstracted from the source of the data, which makes it possible to gather data from all of these systems to provide a single coherent picture, without the consuming application needing to know where the data is stored, or how to get the data from each source system.
It is important to note that no actual data is stored in IFS OI Server, data is left in the source systems and is requested on demand. The Data Broker is the key component that allows a consuming application (such as IFS OI Explorer) to communicate with disparate systems through a single interface.
Data Dictionary
The Data Dictionary is a conceptual component that exists in the database schema, and acts as a layer that allows users to configure a metadata model of what each real-world object (such as a well or pump) should represent, as well as attributes that are common to that object.
In the Data Dictionary, real-world objects are known as entities. Hierarchical structures in the Data Dictionary connect related entities, while templates describe the characteristics of each asset in terms of attributes, resulting in a comprehensive asset model. The Data Dictionary structures can model entire corporations, with all entities described right down to the level of tag values.
Once the model is defined, it is linked to data from the source systems. That way data can be referenced via its model (hierarchical and human-friendly) instead of its name in the source system (which may consist of letters and numbers). Consider the following example:
A tag 015AC114ZH.PV in the source system, might actually represent the Tubing Head Pressure of well BOSSIER. Once configured, we can use the Data Dictionary to retrieve BOSSIER:THP, instead of having to use the source system name.
You can build a reference model for an entire corporation with a hierarchical view of all equipment, processes, and measures connected into the Data Dictionary. This can be built up over time to leverage the information from all areas within an operation. Through hierarchical pages and calculations, you can even target all assets of a type, or all assets from a point in the hierarchy.
The Data Dictionary also stores information about data systems and the method or configuration used to fetch data from those systems. IFS OI Server accesses actual data from the source system only when a consuming application requests it.
From an application viewpoint, when requests for data are made, the IFS OI Server infrastructure locates that data, and the way by which it can be retrieved, from the Data Dictionary.
IFS OI Server Database
The IFS OI Server database is a Microsoft SQL Server database that stores the configuration of the Data Dictionary and all of the other information that is required by IFS OI Server components to operate.
Calculation Engine
The Calculation Engine transforms existing data retrieved from an external system to allow for complex, time-based analysis of production data.
 It provides advanced calculation functionality that allows users to combine existing data, and derive new entities that aid in analysing existing data.
It provides advanced calculation functionality that allows users to combine existing data, and derive new entities that aid in analysing existing data.
This allows us to run calculations over multiple assets in a hierarchy to get production figures that take into account the time periods a piece of equipment was contributing.
For example, if an organisation cycles their wells between water injectors and oil producers, the Calculation Engine can analyse the hierarchy to get production figures that are aware of the production periods for each specific entity.
API
The IFS OI Server API is the public API for IFS OI Server. It provides a RESTful web services interface that serves up the structure and data provided by the Data Broker and Data Dictionary.
 Via this interface, users are able to get information about real world objects in the system, the structure of these objects, and the relationships between objects.
Via this interface, users are able to get information about real world objects in the system, the structure of these objects, and the relationships between objects.
The API is the entry point into IFS OI Server to get any data or structure information, and is used for other IFS OI and third party applications. It also provides features to model the relationships between objects from other IFS OI systems, giving the ability to aggregate a total relationship map at a higher level than the Data Dictionary. In this way, all other IFS OI applications can contribute to this relationship graph, expanding it out further than just the knowledge that is inside IFS OI Server.
Server Management
IFS OI Server Management is a web-based enterprise management tool that has been created to simplify administration of the IFS OI Server Data Dictionary.
It allows administrators to create and configure:
- Hierarchies
- Entities
- Templates and Attributes
- Datasources (tags and datasets)
- Calculations
It also allows bulk import and export of this configuration.