ON THIS PAGE:
This article is about datasources and adaptors in IFS OI Server, the associated terminology, and how they work. For details on how to create datasources, see: Creating a Dataset Datasource, Creating a Tag Datasource.
What is a datasource?
A datasource is a connection between IFS OI Server and an external system that contains data that we want to access. These systems are the master storage location of that data, so how do we surface this data through IFS OI Server?
Adaptors are the answer
An adaptor is a component of IFS OI Server that enables the gathering of data from external sources. Each of the adaptors in IFS OI Server are written for a specific type of external system. For example, there is an adaptor for PI historians, an adaptor for PHD historians, and even generic adaptors to connect to SQL Server or Oracle databases.
It is this adaptor principle that allows IFS OI Server to be so flexible in being able to connect to so many different types of source systems to get data.
Available Adaptors
This is a list of the adaptors currently available in IFS OI Server:
| Time Series Adaptors | Dataset Adaptors |
How do we connect to an external system in IFS OI Server?
A datasource must exist in IFS OI Server for every external system that is to be connected. When you configure a datasource, it uses an adaptor to create a connection to the external system.
To communicate successfully with any of these systems, we need to be able to give it some information, things like server names, user names, passwords, etc. In IFS OI Server these pieces of information are called parameters, and these can vary from one datasource to the next.
Below is an example of the configuration screen in IFS OI Server Management, showing some of the high level configuration and parameters.
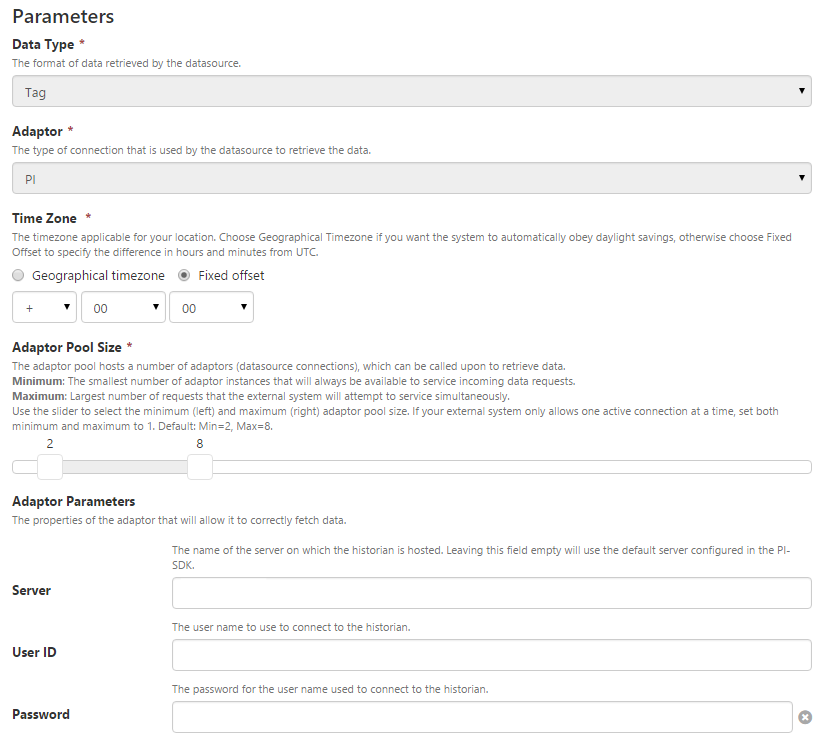
Parameters
Some of the parameters can make a big difference to the performance of the data source when we tune them correctly.
One of these parameters that is present on all adaptors, is the Adaptor Pool Size parameter.
About Adaptor Pools
The Adaptor Pool Size allows you to specify the minimum and maximum number of instances of this type of adaptor that will be available in memory in IFS OI Server. This is related to the number of simultaneous connections available to that data source. It’s important to note that this setting is for this configuration of the adaptor. If you configure two PI adaptors, there will be 2 adaptor pools, one for each of them.
The minimum is important because it does take an amount of memory to store each of these adaptor instances. So if the minimum value is high, for all adaptors, then it will consume more RAM on the web server.
The maximum is important because when the load on the server increases, we can load up more instances of the adaptor and run the requests for data in parallel, which gives us more speed. But, at the same time, we don’t want to overload the data source, so we provide this upper limit.
When IFS OI Server detects that the adaptors in the pool are not being used, it reduces the number of adaptors in the pool back down to the minimum to save memory. So, something to consider is that it will take small amount of time when a new instance of the adaptor gets created in memory and added to the pool. If you set your limit too low and you get a lot of simultaneous requests from this one data source, there will be a small lag as each new adaptor gets added to the pool.
So there is a balancing act here between memory use on the web server, performance of gathering data, and not putting too much load on the source system.
Identifying external systems
One of the more advanced, but very useful, features of a tabular datasource in IFS OI Server is a concept known as a System Identifier. This enables IFS OI Server to translate an entity name in IFS OI Server, to the equivalent name in each of the source systems.
Let's take an example. We have an entity in IFS OI Server, called Well_1. This same well may be known as W1 in IFS OI Production and Well1 in Qbyte. Now these are different names, so how can we tie these all back together? In IFS OI Server we can create a mapping between an entity, and an equivalent name in each datasource (so we can have one mapping for each datasource).
So how does it work? When you request data for Well_1, from the IFS OI Production datasource, IFS OI Server will substitute the entity name Well_1 with W1 in the SQL statement being executed in the dataset. When the data is returned, IFS OI Server automatically adds an extra column to the returned data, with the original entity name included, completing the conversion in both directions.